Głównym obszarem badań teorii inteligentnego projektu (ID – intelligent design) jest wykrywanie istnienia projektów, czyli celowych działań inteligencji. Najciekawszym polem do tego typu działalności jest przyroda. A narzędziami są między innymi wyspecyfikowana i nieredukowalna złożoność; oba wskazują na konieczność istnienia wcześniejszego planu i bardzo precyzyjnego jego wykonania.
Doskonałym przykładem takiego projektu jest łańcuch DNA (kwas deoksyrybonukleinowy). Aby uzmysłowić sobie, jakiej skali jest to projekt, posłużmy się pewną metaforą odległości. Jakiegokolwiek użyć tu przymiotnika: „duża”, „wielka” czy jeszcze innego, to zawsze otrzymamy wielkość względną, bo istnieją znacznie większe liczby, niż te, które pojawiają się w genetyce, jednak na pewno są one duże w kontekście naszych codziennych ludzkich doświadczeń.
Informacja genetyczna człowieka zapisana jest w łańcuchu DNA, który pełni rolę nośnika informacji genetycznej (genomu) organizmów żywych oraz wirusów. Składa się ze szkieletu (deoksyryboza, aldopentoza, cukier prosty 5-węglowy, którego jedną z grup hydroksylowych jest zestryfikowana reszta fosforanowa) oraz zasad azotowych. Informacja kodowana jest właśnie za pomocą określonej kolejności uszeregowania zasad azotowych. W DNA występują cztery rodzaje zasad: dwie puryny (adenina – A i guanina – G) oraz dwie pirymidyny (cytozyna – C i tymina – T). Ludzki (eukariotyczny) łańcuch DNA składa się z dwóch prawoskrętnych spiral (istnieją też lewoskrętne spirale DNA) połączonych ze sobą dopełniającymi się zasadami azotowymi (A z T i G z C). Skręcone spirale nazywa się helisami – stąd określenie DNA jako podwójnie skręconej helisy. Puryna (posiada dwa pierścienie) łączy się zawsze z pirymidyną (ma jeden pierścień) wiązaniem wodorowym. W każdym miejscu łańcucha może znajdować się dowolna z tych czterech zasad azotowych: A, C, T lub G, jednak zawsze łączą się one w takie same pary w drugiej komplementarnej (dopełniającej) helisie. Te pary to: A-T oraz G-C (w kwasie RNA guanina zostaje zastąpiona przez uracyl – U). I tak dzieje się zawsze, dlatego znając kolejność występowania zasad azotowych w jednej spirali, zawsze wiemy, jaka jest kolejność występowania zasad w drugiej spirali.
(I) GAGAAACGGGA
To po połączeniu obu spiral powstaje podwójna helisa:
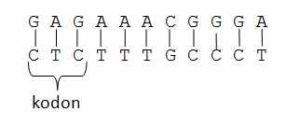
Trzy kolejne zasady azotowe kodują aminokwas. Takie trójki zasad nazywane są kodonami1. W ludzkim organizmie mamy 20 rodzajów aminokwasów. Na przykład aminokwas alanina kodowany jest przez kodony GCU (guanina-cytozyna-uracyl), GCC, GCA lub GCG, lizynę koduje AAA lub AAG – przyporządkowanie nie jest jednoznaczne, co umożliwia częściowe zabezpieczanie się przed mutacjami.
DNA człowieka
Szacuje się, że ludzki łańcuch DNA zawiera około 3,2 miliarda (3,2 x 109 = 3 200 000 000)2 par zasad (komórki haploidalnej). Kolejność zasad decyduje o informacji genetycznej zakodowanej w DNA. Ludzkie DNA podzielne jest na 23 pary chromosomów (łącznie 2 x 23 = 46 chromosomów). Najdłuższy jest chromosom nr 1 zawierający około 249 milionów (249 000 000) par zasad (pz)3. Szacuje się, że gdyby wszystkie te 46 chromosomów połączyć w jeden łańcuch i go rozciągnąć, to miałby on długość około 2 metrów. W rzeczywistości jest on bardzo gęsto upakowany (zwinięty), bo prawie każda4 z bilionów5 komórek w naszym ciele zawiera w jądrze komórkowych i w rybosomach materiał DNA. Poszczególne części łańcucha DNA pełnią różne funkcje, z których większość jest obecnie tylko częściowo rozpoznana. Historycznie najpierw zidentyfikowano geny kodujące białka.
Genów kodujących białka jest tylko około 1,5%. Pozostałe ponad 98,5% genów to DNA niekodujące. Początkowo nazywano je nawet „śmieciowym DNA”; obecnie wiemy, że pełni ono bardzo ważne funkcje, chociaż na razie są one tylko częściowo poznane. Czyli DNA oprócz informacji o tym, jak połączyć ze sobą aminokwasy, aby zbudować białka (geny kodujące6), zawiera informacje o tym, w jakich okolicznościach tworzyć dane białko, jak intensywnie i jak długo je wytwarzać, gdzie je przesłać (do mitochondriów czy do wakuoli) oraz w których tkankach jaki rodzaj białek ma powstać7. Warunkiem prawidłowego rozwoju organizmu jest to, aby informacje zakodowane w DNA były bezbłędnie (prawie – bo występujące mutacje genetyczne „psują” sekwencję DNA) i powielane (replikowane) do wszystkich nowo powstających komórek. A dzieje się to bezustannie każdego dnia. Czyli powstają biliony kopii łańcucha DNA.
Metafora łańcucha o długości 3200 kilometrów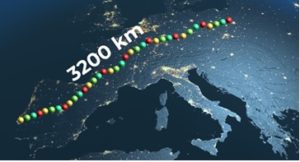
Gdybyśmy powiększyli nasz łańcuch DNA, tak aby rozmiar pojedynczej pary zasad miał długość 1 milimetra, to wówczas cały łańcuch DNA miałaby około 3200 kilometrów8. Byłby tak długi, że sięgałby ze środkowej części Polski do Lizbony w Portugalii. Wyobraźmy sobie taki łańcuch z koralikami ułożony przez pół Polski, dalej przez Niemcy, Francję, Hiszpanię i Portugalię.
Przejechanie tej trasy samochodem zajęłoby nam ponad 30 godzin (jadąc średnio nieco ponad 100 km/h). Gdybyśmy postawili sobie za zadanie ułożenie takiego łańcucha (np. tylko jednej helisy) składającego się z czterech rodzajów koralików odpowiadających czterem rodzajom zasad azotowych (A, C, G i T), gdzie mielibyśmy koraliki w czterech kolorach, wówczas układając po jednym koraliku na sekundę, zajęłoby nam to 3,2 miliarda sekund, czyli około 100 lat9. Wyobraźmy sobie, że idziemy przez 100 lat z Polski do Portugalii i co sekundę układamy jeden paciorek: zielony, żółty, żółty, czerwony, turkusowy, zielony, zielony i tak dalej, w idealnie ustalonej dla tych ponad 3 miliardów kuleczek kolejności.
Bardzo złożony mechanizm – dobrze zaprojektowany
W tym miejscu nasuwa się pytanie: jaki mechanizm mógł przygotować i codziennie 24 godziny na dobę wykonywać prawie bezbłędnie to zadanie? A przecież łańcuch DNA znajduje się w prawie każdej komórce naszego ciała. Proces tworzenia tak ogromnej porcji informacji musi być niesamowicie złożony i powtarzalny. Każda pomyłka może prowadzić do powielenia mutacji, które na ogół są „naprawiane” (kolejny niezwykle złożony mechanizm). Czy coś takiego mogło powstać w sposób losowy, bez planowania i udziału inteligencji, tylko na zasadzie przypadkowych, kumulatywnych zmian? Czy sam dobór naturalny może stanowić wyjaśnienie dla powstanie i złożoności ludzkiego genomu? Tym bardziej że czas, jakim dysponuje dobór, jest ograniczony – działa on tylko na podstawie tego, co już istnieje. Wszystko to prowadzi do kolejnych trudności. Naturalistyczne scenariusze powstania i rozwoju życia na Ziemi nadal nie dostarczają wiarygodnej odpowiedzi na pytanie: jak powstała pierwsza żywa komórka?
I najważniejsze pytanie: w jakim celu jakiś niemal mityczny, ślepy proces darwinowski miałby przygotowywać tak gigantyczną ilość informacji bez zaplanowania (przewidywania), do czego mogą być one potrzebne w zupełnie innych komórkach organizmu? Bo przecież komórka tkanki nerki zawiera informację genetyczną wykorzystywaną do powstawania tkanki soczewki oka. Tkanka nerki nie potrzebuje tych informacji, bo nie wytwarza soczewki oka. Jest to zbędny balast, a nie przewaga w wyścigu, gdzie „najlepiej przystosowani przetrwają”.
Żywe organizmy ukrywają w sobie ogromne ilości informacji, starannie zaplanowanych i precyzyjnie przetwarzanych, a łańcuch DNA jest przykładem jednego z projektów w przyrodzie.
Robert Olender
Źródło zdjęcia: Pixabay
Ostatnia aktualizacja strony: 13.10.2020
Przypisy
- Mamy w tym przypadku do czynienia z informacją kodowaną cyfrowo, w systemie czwórkowym (cztery symbole: A, C, G, i T zapisane na trzech pozycjach). Umożliwia to zakodowanie 64 symboli (liczb czwórkowych), bo 43 = 64.
- Genom ludzki wcale nie jest wyjątkowo długi. Genom sosny taedy jest siedem razy dłuższy, bo posiada ponad 20 miliardów par zasad (por. A. Zimin et al., Sequencing and Assembly of the 22-gb Loblolly Pine Genome, „Genetics” 2014, Vol. 196, No. 3, s. 875–890 [dostęp 6 IX 2020]).
- Chromosomy uszeregowane zostały według ich długości, stąd pierwszy jest najdłuższy, a czterdziesty szósty (ostatni) najkrótszy (jest to chromosom Y ‒ „męski”; kształtem trochę przypomina literę Y). Jak wiadomo, kobiety na ostatniej parze chromosomów mają dwa chromosomy XX, a mężczyźni XY.
- Na przykład erytrocyty (czerwone ciałka krwi – odpowiadają za transport tlenu z płuc do innych części organizmu) nie zawierają DNA, dlatego nie mogą się rozmnażać i po około 120 dniach (3 miesiącach) obumierają.
- Ciągle nie wyliczono dokładnie, ile komórek zawiera ludzkie ciało. Zresztą zależy to oczywiście od budowy i wagi danego człowieka. Przybliżone szacunki określają liczbę komórek na od 600 miliardów (600 x 109) do 70 bilionów (70 x 1012 ‒ ta liczba wynika z podzielenia 70 kg wagi ciała przez 1 nanogram, jako szacowany ciężar jednej komórki). Zwykle podaje się, że w ciele 70-kilogramowego człowieka znajduje się około 50 bilionów komórek (50 000 000 000 000).
- Ponieważ genów kodujących w ludzkim genomie mamy nieco ponad 20 000, a rodzajów białek około 100 000, dlatego niekodujące DNA musi być też do tego w jakiś sposób wykorzystywane (ten mechanizm nie został jeszcze odkryty).
- Chociaż kod DNA jest identyczny w każdej komórce naszego ciała, to w komórkach każdej z prawie 200 rodzajów tkanek (podzielnych na cztery grupy: nabłonkowe, mięśniowe, nerwowe i łączne) wytwarzane są inne tkanki.
- 1 cm = 10 mm, 1 m = 103 mm, 1 km = 106 mm, a 1000 km = 109 mm.
- 1 godz. = 3600 s, 24 godz. = 24 x 3600 = 86 400 s, 1 rok = 365,25 x 86 400 = 31 557 600 s, 100 lat = 3,156 mld s.
Napisał Pan:
„I najważniejsze pytanie: w jakim celu jakiś niemal mityczny, ślepy proces darwinowski miałby przygotowywać tak gigantyczną ilość informacji bez zaplanowania (przewidywania), do czego mogą być one potrzebne w zupełnie innych komórkach organizmu? Bo przecież komórka tkanki nerki zawiera informację genetyczną wykorzystywaną do powstawania tkanki soczewki oka. Tkanka nerki nie potrzebuje tych informacji, bo nie wytwarza soczewki oka. Jest to zbędny balast, a nie przewaga w wyścigu, gdzie „najlepiej przystosowani przetrwają”.”
Ale mnie się wydaje, że ten fakt jest bardzo dobrym argumentem, że nie ma w tym żadnego celu, że to rzeczywiście „zaprojektowal” bezmyślny proces. Gdyby to projektowała jakaś inteligencja, to w komórkach każdego rodzaju znajdowałaby się tylko ta informacja, której się tam używa.
Chyba, że jest to rzeczywiście jakiś zbędny balast, jak Pan napisał. A jest? W czym przeszkadza istnienie tej dodatkowej informacji genetycznej? Bo jeśli nie przeszkadza, to dobór po prostu jej nie wykrywa.
I ostatnia uwaga. Pan przedstawił, jak to Dawkins nazwał, Dowód z Niedowierzania („to jest tak wielkie, tak wspaniałe, tak precyzyjne – jak to mogło samo powstać?”). W „Ślepym zegarmistrze” Dawkins skutecznie taki dowód wyśmiał pokazując moc ewolucji kumulatywnej. Wydaje się, że lepszym argumentem niż Dowód z Niedowierzania byłoby pokazanie, że ta struktura nie mogła powstać bez udziału inteligencji.
Bardzo dziękuję za komentarz. Ten pierwszy argument „Gdyby to projektowała jakaś inteligencja, to w komórkach każdego rodzaju znajdowałaby się tylko ta informacja, której się tam używa.” jest bardzo często podnoszony przez przeciwników projektu. Sprowadza się on w gruncie rzeczy do stwierdzenia, że wszechświat nie może być zaprojektowany, bo gdyby był, to zostałby zaprojektowany lepiej (optymalnej). Jednak projektant wcale nie musi kierować się ludzką logiką, rozstrzygająca co jest bardziej optymalne. Ponadto, teoretyczne istnienie 200 wersji DNA, różnych dla każdego rodzaju komórki, powodowałby wiele potencjalnych problemów. Na przykład łączące się gamety (plemnik i jajeczko) musiałby zawierać wszystkie 200 wersji tych uproszczonych DNA (każdy konstruktor wie, że 200 różnych rodzajów części to wielokrotnie więcej potencjalnych problemów).
Ustosunkowując się do drugiej uwagi. Faktycznie może lepszym argumentem niż Dowód z Niedowierzania, jest konieczność zaprojektowania całego sytemu DNA, do czego potrzebna jest inteligencja.
Jeszcze raz dziękuję za merytoryczny komentarz.
„teoretyczne istnienie 200 wersji DNA, różnych dla każdego rodzaju komórki, powodowałby wiele potencjalnych problemów. Na przykład łączące się gamety (plemnik i jajeczko) musiałby zawierać wszystkie 200 wersji tych uproszczonych DNA (każdy konstruktor wie, że 200 różnych rodzajów części to wielokrotnie więcej potencjalnych problemów).”
Zaszło nieporozumienie. Oczywiście, wiele wersji DNA byłoby niepotrzebnym balastem utrudniającym (chyba nawet uniemożliwiającym) rozwój zarodka, gdzie komórka totipotencjalna, jaką jest zygota, przekształca się stopniowo we wszystkie rodzaje komórek dojrzalego ciała. Tu wymagana jest jedność kodu genetycznego. Chodziło mi o to, o czym Pan pisał – czyli o to, że np. komórka w palcu ma informację na temat komórek nerek czy oczu, chociaż nigdy z tej informacji nie skorzysta (chyba?). Ten balast informacyjny jest pewnie nieszkodliwy i dlatego dobór naturalny go nie wyłapuje. To wskazuje albo na naturalistyczną ewolucję, albo – jak Pan pisał – na Mało Inteligentnego Projektanta (MIP). Chyba że usuwanie czegoś, co i tak jest nieszkodliwe, wymagałoby dodatkowego mechanizmu, co niepotrzebnie komplikuje projekt. A prostota projektu jest też oznaką inteligencji.
Warto też pamiętać, że teoria inteligentnego projektu nie stwierdza, że cała przyroda ożywiona została inteligentnie zaprojektowana (to głoszą tylko niektórzy kreacjoniści). Teoria ID zostawia niekierowanym procesom ewolucyjnym całkiem sporo miejsca. Za inteligentnie zaprojektowane uznaje ona tylko to, co można ze sporym prawdopodobieństwem wykazać.
Prof. Jodkowski napisał:
„Gdyby to projektowała jakaś inteligencja, to w komórkach każdego rodzaju znajdowałaby się tylko ta informacja, której się tam używa.”
Wydaje mi się, że bazuje to na założeniu, że w każdej komórce jej DNA zawiera 'plan budowy’ całego organizmu. Pytanie zatem z punktu widzenia projektu po co każda komórka miałaby zawierać pełny plan budowy całego organizmu, jeśli taka komórka pełni tylko wyspecjalizowaną funkcję? Jak pewne jednak jest to założenie? Wiemy, że DNA koduje pierwszorzędową sekwencję białek. Ale od sekwencji aminokwasów do organizmu to droga bardzo daleka, analogicznie jak przepis na stworzenie cegły nie powie nam wiele jak zbudować dom. W tej perspektywie komórka zawierałaby w swoim DNA tylko minimalną konieczną informację – stąd jej obecność wśród większości komórek. Proces, który faktycznie kieruje rozwojem osobniczym byłby zaś ulokowany gdzie indziej.
Pan Olender napisał:
„Szacuje się, że ludzki łańcuch DNA zawiera około 3,2 miliarda (3,2 x 109 = 3 200 000 000)2 par zasad (komórki haploidalnej).”
Zwrócił Pan uwagę na ciekawy problem fizycznego upakowania tak długiej helisy w komórkach – sama mechanizacja tego procesu wymaga niebagatelnej kontroli. Natomiast jeśli chodzi o zawartość informacji w genomie to z informatycznego punktu widzenia nie mam jej tak dużo: jak Pan pisał możliwe są 4 różne możliwe połączenia par zasad: A-T, T-A, G-C i C-G. W genomie mamy około 3 miliardy par zasad. By wyrazić informację zapisaną w DNA w kodzie cyfrowym (binarnym) do każdej kombinacji par zasad musimy przypisać 2 bity. Ilość możliwych kombinacji 2 bitów to 4 (00, 01, 10, i 11), zatem każda pojedyncza para zasad reprezentuje 2 bity. Wynika z tego, że 3 miliardy par zasad to 6 miliardów bitów, czyli 800 megabajtów. To jest maksymalna teoretyczna możliwa pojemność informacyjna genomu: faktyczna będzie nieco mniejsza ze względu na fragmenty uszkodzone czy niefunkcjonalne. Trzy razy mniej niż wersja Microsoft Office, nie wspominając nawet o innym specjalistycznym oprogramowaniu, a trudno przecież przypuszczać by 'instrukcje budowy’ organizmu były mniej złożone niż oprogramowanie biurowe.