Po transkrypcji, zanim uwolniony RNA trafi z jądra do cytoplazmy, podlega on kilku ważnym modyfikacjom. Takie modyfikacje określa się mianem „dojrzewania” pierwotnego transkryptu. Trzeba pamiętać, że rodzajów RNA, w zależności od funkcji, jest całkiem sporo. Tak więc u bakterii mRNA, czyli ten, który niesie informację o białku, podlega niewielkim poprawkom lub też pozostaje niezmieniony. Inaczej ma się sytuacja z rybosomowym RNA czy też transportującym RNA. Pierwotny transkrypt zostaje podzielony na części: różne rodzaje rRNA i pojedynczy tRNA (lub jego kopie) oraz regiony rozdzielające tak zwane spacery.
Innym rodzajem zmian pierwotnego transkryptu, dotyczącego tRNA, jest dodanie do jego końca 3’ sekwencji nukleotydów CCA (cytozyna-cytozyna-adenina). Jest to fragment niezbędny do pełnienia funkcji transportującego RNA, bowiem to właśnie do tej końcówki przyłącza się aminokwas, który niebawem zostanie przyłączony do produkowanego białka.
Jeszcze jeden rodzaj modyfikacji dotyczy zmian strukturalnych zasad azotowych i reszt cukrowych (rybozy), na przykład ich metylacji, czyli dołączania grup alkilowych (metylowych) (-CH3).
Najważniejszymi procesami dojrzewania u eukariota jest dodawanie na końcu 5’ specjalnego zakończenia tak zwanego capu lub czapeczki, ogona poli (A) do końca 3’ oraz splicing. Pierwszą zmianą, dokonywaną już w czasie transkrypcji, jest utworzenie na jednym z końców tak zwanej czapeczki. Jej zadaniem jest stabilizacja RNA oraz ochrona przed enzymami degradującymi transkrypt. W przeciwieństwie do bakteryjnych transkryptów, w komórkach eukariotycznych dochodzi do przyłączenia struktury tak zwanego ogona poli (A). Zabieg ten nosi nazwę poliadenylacji. Chociaż dokładna rola ogona poli (A) nie jest do końca znana, to jednak wiadomo, że wpływa on na stabilność transkryptu oraz pomaga w jego transporcie z jądra do cytozolu.
Intensywność dojrzewania pierwotnego transkryptu jest zależna od funkcji RNA, którą niebawem będzie pełnić. Skupmy się przede wszystkim na RNA, który niesie ze sobą informację o białku (mRNA). W niedojrzałej formie, czyli pre-mRNA, zbudowany jest z odcinków – kodujących egzonów i niekodujących intronów. Dojrzewanie transkryptu polega między innymi na składaniu (splicingu), czyli rozcięciu transkryptu, w celu usunięcia intronów i połączenia ze sobą egzonów. Taki mRNA zbudowany wyłącznie z sekwencji kodujących nazywany jest otwartą ramką odczytu, co ma później znaczenie przy procesie translacji (syntezy białka). Bywa, że taki splicing zachodzi w sposób automatyczny, a więc bez udziału innych cząstek, lub też przy udziale struktur złożonych z białek oraz czterech małocząsteczkowych RNA – snRNA, czyli tak zwanych splicesomów. Wycinane introny mają różną długość, ale zazwyczaj zaczynają się sekwencją GU (guanina-uracyl), a kończą AG (adenina-guanina). Jest to oczywisty sygnał do wycięcia danego fragmentu. Za usuwanie intronów odpowiadają kompleksy białek z snRNA (ang. small nuclear RNA, małe jądrowe RNA), tak zwane snRNP.
Wycinanie sekwencji niekodujących i łączenie ze sobą kodujących fragmentów przynosi wiele korzyści, bowiem odcinki te mogą być ze sobą łączone w dowolnej kolejności, zwiększając tym samym różnorodność uzyskiwanych mRNA, a w konsekwencji niezliczoną ilość odmiennych końcowych produktów – białek – pochodzących z jednego genu.
„Czas życia” pojedynczego RNA jest różny i zależy od jego składu nukleotydów oraz rodzaju komórki, w której powstał. Niektóre transkrypty żyją do 30 minut, inne nawet do 10 godzin. Dłuższy czas trwania RNA sprzyja zwiększonej syntezie danego polipeptydu.
Translacja: kod genetyczny, tRNA, rybosomy
RNA niosący ze sobą informację genetyczną, po właściwych modyfikacjach, może zostać przetransportowany do cytoplazmy i poddany procesowi syntezy białka, czyli translacji. To proces, w którym wykorzystuje się inny „alfabet” niż w dotychczas poznanych procesach replikacji czy transkrypcji, bowiem język nukleotydów jest tłumaczony na język aminokwasów.
W drugiej połowie ubiegłego wieku trwały intensywne prace nad rozkodowaniem systemu tłumaczenia języka nukleotydów na język aminokwasów. W artykule traktującym o historii odkryć związanych z DNA możemy przeczytać:
W 1957 roku Crick zaproponował hipotezę cząsteczki adaptorowej, która tłumaczyła zdolność tRNA do tłumaczenia informacji genetycznej. Gdyby reszta aminokwasowa kodowana była przez dwie zasady, możliwych byłoby jedynie 16 kombinacji, podczas gdy czteronukleotydowy dawałby zbyt wiele możliwości. Jako najbardziej prawdopodobny rozważano kod trójkowy. Hipoteza ta została poparta eksperymentami in vivo, z wykorzystaniem zmiany ramki odczytu podczas translacji, oraz in vitro, z wykorzystaniem aminoacylo-tRNA rozpoznających określone trójki zasad1.
Ponieważ w białkach występuje 20 różnych aminokwasów, najbardziej pasującym wariantem kodowania okazał się system trójkowy, w którym trzy nukleotydy kodują jeden aminokwas. Po przeliczeniu widać, że mamy aż 64 kodony, z czego jeden stanowi sekwencję startową translacji (kodon ten koduje metioninę), a trzy kodony to tak zwane kodony STOP, zatrzymujące syntezę białka, ale nie kodujące żadnego aminokwasu. Zatem 61 kodonów koduje 20 aminokwasów. Łatwo z tego wywnioskować, że pojedynczy aminokwas jest kodowany przez więcej niż jeden kodon. Wyróżniono kilka cech tego kodu genetycznego:
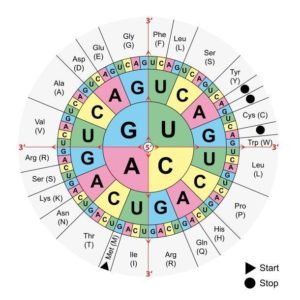
trójkowy – trzy nukleotydy kodują jeden aminokwas, to znaczy każde trzy nukleotydy w sekwencji mRNA dająRys. 7. Rys. 11. Schemat kodu genetycznego, który należy odczytywać od środka koła, gdzie znajdują się cztery nukleotydy, kierując się do zewnątrz. Należy pamiętać o tym, że kod genetyczny jest zdegenerowany, czyli dopuszcza się dowolność wstawionego nukleotydu na trzecim miejscu w kodonie, przykładowo dla aminokwasu waliny mamy kodony GUU, GUC, GUG. Źródło obrazka: https://tiny.pl/9hnz1 [dostęp: 24.06.2021].informację o jednym aminokwasie;
jednoznaczny – pojedyncza trójka nukleotydów koduje jeden, zawsze ten sam aminokwas, na przykład kodon startowy AUG koduje metioninę;
zdegenerowany – kilka różnych kodonów koduje ten sam aminokwas, na przykład istnieje sześć różnych sposobów na „zapisanie” leucyny w języku mRNA. Wszystkie kombinacje zebrano w tabeli kodu genetycznego (Rys. 7);
niezachodzący – trójki nukleotydów nie nakładają się na siebie;
bezprzecinkowy – pomiędzy kodonami nie ma żadnych fizycznych ani chemicznych przerw;
kolinearny – kolejność ułożenia trójek kodujących w kwasie nukleinowym odpowiada kolejności ułożenia aminokwasów w białku;
uniwersalny – u wszystkich organizmów żywych występuje taki sam kod genetyczny, co umożliwiło rozwój inżynierii genetycznej.
Bezprzecinkowość kodu genetycznego jest jego bardzo ważną cechą, bowiem z pozoru drobna pomyłka na wcześniejszym etapie transkrypcji (np. ominięcie jednego nukleotydu) prowadzi do przesunięcia tak zwanej fazy odczytu lub ramki odczytu, dając w efekcie zupełnie inną sekwencję aminokwasów w białku.
Cząsteczką adaptorową, o której wspominał Francis Crick, jest transportujący czy też transferowy RNA (tRNA). Łańcuch tRNA jest pofałdowany, a pewne jego rejony oddziałują ze sobą, tworząc strukturę przypominającą czterolistną koniczynę. Z fragmentów istotnych z punktu widzenia przebiegu translacji jest tak zwany antykodon – sekwencja trzech nukleotydów, która tworzy komplementarną parę z trzema następującymi po sobie nukleotydami w mRNA. Drugim rejonem niedopasowanych zasad w tRNA jest sekwencja znajdująca się na końcu 3’. Do tego właśnie fragmentu wiąże się aminokwas odpowiadający trójce nukleotydów obecnych w antykodonie.
Jedną z właściwości kodu genetycznego jest jego tak zwane zdegenerowanie, czyli możliwość kodowania jednego aminokwasu przez więcej niż jeden kodon. Uściślając, jeden aminokwas może być rozpoznawany przez więcej niż jeden tRNA, a jedna cząsteczka tRNA rozpoznaje więcej niż jeden kodon. Jest to możliwe dzięki tak zwanej zasadzie tolerancji lub chwiejności w trzeciej pozycji kodonu. Oznacza to, że tak naprawdę najważniejszą rolę w translacji odgrywają dwa pierwsze nukleotydy, z przymrużeniem oka traktując ostatnią pozycję w kodonie.
Aby aminokwas mógł przyłączyć się do końca 3’ tRNA, muszą zadziałać odpowiednie enzymy. Takimi molekułami są syntetazy aminoacylo-tRNA, specyficzne dla każdego aminokwasu. Oznacza to, że takich enzymów jest 20 – po jednym dla każdej nowo włączanej do łańcucha cząsteczki. Odpowiednia syntaza katalizuje reakcje utworzenia wiązania między tRNA a aminokwasem. Antykodon tRNA wiąże się z odpowiednim kodonem na zasadzie komplementarności zasad: adenina z uracylem, guanina z cytozyną. Aby jednak cały proces mógł zajść, potrzebny jest jeszcze molekularny aparat stanowiący swego rodzaju płaszczyznę, na której odbywa się translacja – rybosom. Jest to kompleks wielu białek tak zwanych rybosomowych oraz RNA rybosomowego, który wyglądem przypomina spłaszczonego grzybka. Części rybosomów są zazwyczaj produkowane w jąderku, a następnie transportowane do cytozolu. Rybosomy również występują w mitochondriach i chloroplastach – te produkowane są wewnątrz tychże organelli. Podział na podjednostkę mniejszą i większą ma oczywiście odzwierciedlenie w funkcji: w czasie translacji obie podjednostki są ze sobą połączone – mała podjednostka odpowiada za dopasowanie cząsteczek tRNA do mRNA, zaś duża odpowiada za przyspieszanie reakcji tworzenia wiązań peptydowych między kolejnymi aminokwasami, wydłużając tym samym powstający łańcuch peptydowy przyszłego białka. Kompletny rybosom posiada jedno miejsce wiązania mRNA, trzy miejsca wiązania tRNA, nazwane kolejno A, P i E.
Rybosomy występujące w stanie wolnym odpowiadają za produkcję białek, których potrzebuje komórka. Aparaty te mogą być także związane z organellum komórkowym, jakim jest siateczka śródplazmatyczna. Białka wychodzące spod tak usytuowanych rybosomów to zazwyczaj białka kierowane na eksport z komórki, na przykład hormony białkowe, białka wchodzące w skład błon biologicznych oraz białka enzymatyczne.
Translacja: od RNA do białka
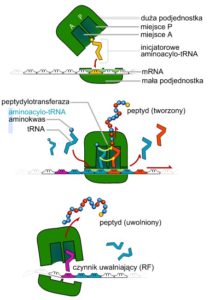
Rys. 8. Ogólny zarys procesu translacji. Źródło obrazka https://tiny.pl/9hkhx [dostęp: 24.06.2021].
Translacja, podobnie jak poznane wcześniej dwa procesy: replikacji i transkrypcji, podzielona jest na trzy etapy: inicjację, transkrypcję oraz translację (Rys. 8).
Proces przepisywania języka nukleotydów na język aminokwasów zwykle rozpoczyna się od końca 5’ mRNA kodonem określanym mianem startowego. Miejsce startu translacji jest niezwykle ważne, gdyż to ono określa już wcześniej wspomnianą ramkę odczytu. Wyobraźmy sobie zdanie: Początkowodanie smakuje. Jeśli zaczęlibyśmy je czytać od zaznaczonego na zielono fragmentu, zdanie uzyskałoby zupełnie inny sens (woda nie smakuje). Podobnie dzieje się w komórce – to, od którego miejsca będzie odczytywany pierwszy kodon, wpływa na całą sekwencję aminokwasową białka.
Proces translacji rozpoczyna się od poskładania wszystkich części w jedną całość, zdolną do przeprowadzenia tego procesu. Startowy tRNA ma zdolność silnego wiązania się z małą podjednostką rybosomu. Mała podjednostka wraz ze startowym tRNA wiąże mRNA i zaczyna przesuwać się wzdłuż mRNA, szukając kodonu startowego. Gdy mała podjednostka natrafi na kodon START, przyłącza się duża podjednostka rybosomu. Powstaje tym samym kompletny aparat przeprowadzający translację. Teraz startowy tRNA znajduje się w miejscu P dużej podjednostki, a do miejsca A może przyłączyć się drugi tRNA z takim aminokwasem, który jest kodowany przez mRNA zaraz za kodonem startowym. Tak rozpoczyna się kolejny etap translacji, czyli elongacja – wydłużanie łańcucha polipeptydowego. Pomiędzy aminokwasami zachodzi reakcja wytworzenia pierwszego wiązania, katalizowana przez dużą podjednostkę rybosomu. Uwolniony pierwszy tRNA przesuwa się do miejsca E, skąd opuszcza aparat translacyjny. Połączone dwa aminokwasy tworzą dipeptyd, który wraz z tRNA przesuwa się z miejsca A do miejsca P, dzięki czemu do miejsca A może przyłączyć się kolejny tRNA z kolejnym aminokwasem. Cały proces można porównać do taśmy produkcyjnej, na której pojawiają się nowe różne elementy potrzebne do produkcji jakiejś maszyny. Każdy z tych elementów musi być „dostarczony” na taśmie przez inny uchwyt. Aby taki element mógł być wbudowany, musi zostać najpierw uwolniony z uchwytu przytrzymującego go na taśmie. Taśma przesuwa się dalej wraz z wolnym uchwytem, gotowym do przytrzymania kolejnego elementu składowego. Tak jak na produkcji, tak i w komórce cały proces powtarza się aż do momentu pojawienia się w miejscu wstawiania tRNA z aminokwasem kodonu STOP. Do takiego kodonu przyłączają się czynniki uwalniające. Ich rolą jest wymuszenie przeniesienia nowo utworzonego łańcucha peptydowego na cząsteczkę wody, dzięki czemu koniec nowo powstałego łańcucha zostaje uwolniony do cytoplazmy. Aparat translacyjny „rozpada się”, by już za chwilę być gotowy do udziału w kolejnej akcji tworzenia białka.
Podsumowanie
Nauka od lat szaleńczo galopuje do przodu, bezustannie poszerzając wiedzę z różnych zakresów życia. Rozwój biochemii jako nauki badającej molekularne podstawy życia rzuca wciąż nowe światło na wiele zagadnień z dziedziny medycyny, analityki czy ochrony środowiska. Dał też początek nauce, jaką jest inżynieria genetyczna, które wykorzystuje zdobytą przez lata wiedzę biochemiczną w tak zwanym modelowaniu genetycznym:
Ludzkość może tworzyć zmodyfikowane gatunki zbóż i roślin uprawnych, odpornych na choroby, wpływ niekorzystnych substancji chemicznych czy też złe warunki środowiska. Inżynieria genetyczna umożliwiła hodowlę zwierząt, które dzięki zwiększeniu produkcji hormonu wzrostu rosną szybciej oraz osiągają większą masę. Co więcej, inżynieria genetyczna znalazła zastosowanie w medycynie – przy wytwarzaniu sztucznej insuliny i leczeniu schorzeń genetycznych2.
Jak wspomniano na początku artykułu, nie sposób omówić chociażby podstaw biologii komórki, procesów w niej zachodzących, różnic międzygatunkowych na kilkunastu stronach pojedynczego artykułu. Na te tematy powstało wiele znakomitych i opasłych książek, między innymi Podstawy biologii komórki Albertsa3, Genomy Browna4, a także wspaniała biblia biochemików Biochemia Stryera5, na bazie których został przygotowany niniejszy artykuł, a które co jakiś czas są uzupełniane.
Pisząc ten artykuł, miałam na względzie zaznajomienie Czytelnika z ogólnym zarysem tego, co dzieje się w komórce. Jest to bardzo bogaty świat, którego jak dotąd wciąż w całości nie poznaliśmy, istnieje ponadto obawa, że nigdy tego nie dokonamy. Opisane tu procesy również ulegają aktualizacjom i uszczegółowieniom zgodnie z wynikami, które uzyskują zespoły naukowców z całego świata.
Nie ulega jednak wątpliwości, że to, co dzieje się w komórce i między komórkami w całym organizmie, to, jak cały ten system reaguje na zmiany środowiska, utrzymując jednocześnie stan równowagi – stanowi niezwykły przykład planu zależności i połączeń, którego wynikiem jest funkcjonalna całość.
Gabryelska i in., DNA – cząsteczka, która zmieniła naukę, s. 111–134.
M. Gołąbek, Przyszłość inżynierii genetycznej – CRISPR-Cas9, „Life Science – Open Space” 2018.
Por. Alberts i in., Podstawy biologii komórki.
Por. T.A. Brown, Genomy, tłum. P. Węgleński, Warszawa 2009.
Por. Stryer i in., Biochemia.
Literatura:
Alberts B. i in., Podstawy biologii komórki, tłum. J. Michejda, J. Augustyniak, Warszawa 1999.
Bartoszek N., Rosowski M., Techniki mikroskopowe w badaniach biologicznych, „Laboratorium – Przegląd Ogólnopolski” 2017, nr 9‒10, s. 12‒21.
Bobrowska-Korczak B. i in., Aktywność telomerazy a dieta, „Bromatologia i Chemia Toksykologiczna” 2017, t. 1, s. 17–24.
Brown T.A., Genomy, tłum. Węgleński, Warszawa 2009.
Bryś M., Ai in., Telomeraza – struktura i funkcja oraz regulacja ekspresji genu, Folia Medica Lodziensia 2012, t. 39, nr 2, s. 293‒326.
Bukowiecka-Matusiak M., Woźniak L.A., Struktura DNA od A do Z. Biologiczne implikacje różnorodności strukturalnej DNA, „Postępy Biochemii” 2006, t. 52, nr 3, s. 1–10.
Chorąży M., Złożoność i hierarchia organizmów żywych, „Nauka” 2011, t. 3, s. 89‒112.
Echols H., Goodman M.F., Fidelity Mechanism in DNA Replication, „Annual Review of Biochemistry” 1991, Vol. 60, s. 477‒511.
Figlerowicz M. et al., Wpływ małych regulatorowych RNA na przebieg zakażeń wirusowych – nowe strategie leczenia zakażeń HCV, „Przegląd Epidemiologiczny” 2006, nr 60, s. 693–700.
Gabryelska M.M. et al., DNA – cząsteczka, która zmieniła naukę. Krótka historia odkryć, „Nauka” 2009, t. 2, s. 111‒134.
Gest H., The Discovery of Microorganisms by Robert Hooke and Antoni Van Leeuwenhoek, Fellows of the Royal Society, „Notes and Records: The Royal Society of London” 2004, Vol. 58, No. 2, s. 187‒201.
Gołąbek M., Przyszłość inżynierii genetycznej – CRISPR-Cas9, „Life Science – Open Space” 2018.
Kalinowska H. i in., Biokataliza, „Kosmos” 2007, t. 56, nr 3‒4, s. 327‒334.
Olszewska M.J., Nukleosomy i regulacja aktywności chromatyny, „Postępy Biochemii” 2010, t. 37, nr 3, s. 657‒670.
Pavlov Y.I. et al., Roles of DNA Polymerases in Replication, Repair, and Recombination in Eukaryotes, „International Review of Cytology” 2006, Vol. 255, s. 41‒132.
Sacharowski S.P. i in., Mechanizmy kontrolujące strukturę chromatyny, „Postępy Biochemii” 2019, t. 65, nr 1, s. 9‒20.
Sutherland J.D. et al., Selective Prebiotic Formation of RNA Pyrimidine and DNA Purine Nucleosides, „Nature” 2020, Vol. 582, s. 60–66.
Stryer L. i in., Biochemia, tłum. Z. Szweykowska-Kulińska, A. Jarmołowski, Warszawa 2009.
Szaleniec M., Rugor A., Enzymy – katalizatory życia, „Wszechświat” 2017, t. 118, nr 4‒6, s. 108‒117.
Wegrzyn D., Deuerling E., Molecular Guardians for Newborn Proteins: Ribosome-Associated Chaperones and Their Role in Protein Folding „Cellular and Molecular Life Sciences” 2005, Vol. 62, No. 23, s. 2727–2738.
Wrzesiński J., Ciesiołka J., Regulacja aktywności katalitycznej rybozymów HDV oraz deoksyrybozymów za pomocą antybiotyków i jonów metali, „Wiadomości Chemiczne” 2018, t. 72, nr 7–8, s. 397–415.